
A continuación, les muestro una herramienta llamada SQLLDR que yo utilizaba, muy útil para hacer ingestas de datos masivos allá por al 2019.
Tenemos nuestro archivo clientes.txt con la información dividida por pipes:

Tenemos nuestra tabla con la siguiente estructura:

Definimos nuestro archivo clientes.ctl de la siguiente manera:
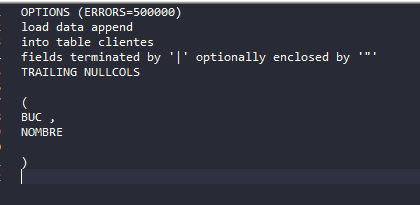
Recordemos que nuestro archivos clientes.txt y clientes.ctl deben tener formato UNIX.
NOTA: Los archivos .txt y .ctl deben estar alojados en el servidor donde se ejecuta el comando sqlldr
Ingresamos al servidor y ejecutamos el siguiente comando:
sqlldr usuario/contraseña@255.255.255.255:22/nombre_base_datos log=clientes.log bad=clients.bad errors=5 control=clientes.ctl data=clientes.txt rows=5 direct=y
Donde:
usuario = Usuario de mi base de datos
Contraseña = Mi contraseña de mi base de datos
255.255.255.255: Es mi ip de mi base datos
22: Es el puerto de mi base de datos
/Nombre de mi base de datos
log= Nombre de mi archivo log
bad= Nombre de mi archivo bad
error= Errores máximos permitidos
control = Nombre de mi archivo .ctl
data= Nombre de mi archivo a cargar
rows = Despues de cuantas columnas se debe realizar un commit.
direct= Si mi ejecución debe o no hacer validaciones. (Los posibles valores pueden ser y/n)
Como podemos observar, nuestra ejecución ha sido exitosa.
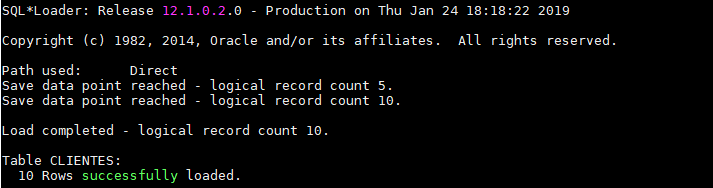
Espero que les haya gustado amigos. Nos vemos en la próxima.